Why So Many Organizations Are Embracing AWS Glue for Data Integration
In today’s data-driven world, organizations are under constant pressure to extract insights faster, integrate data from diverse sources, and build scalable analytics pipelines. Enter AWS Glue—a fully managed, serverless data integration service that’s rapidly becoming a favorite among enterprises, startups, and cloud-native teams alike.
At DappaTechnology, we’ve seen firsthand how AWS Glue is transforming the way organizations handle data engineering. Here’s why it’s gaining so much traction.
What Is AWS Glue?
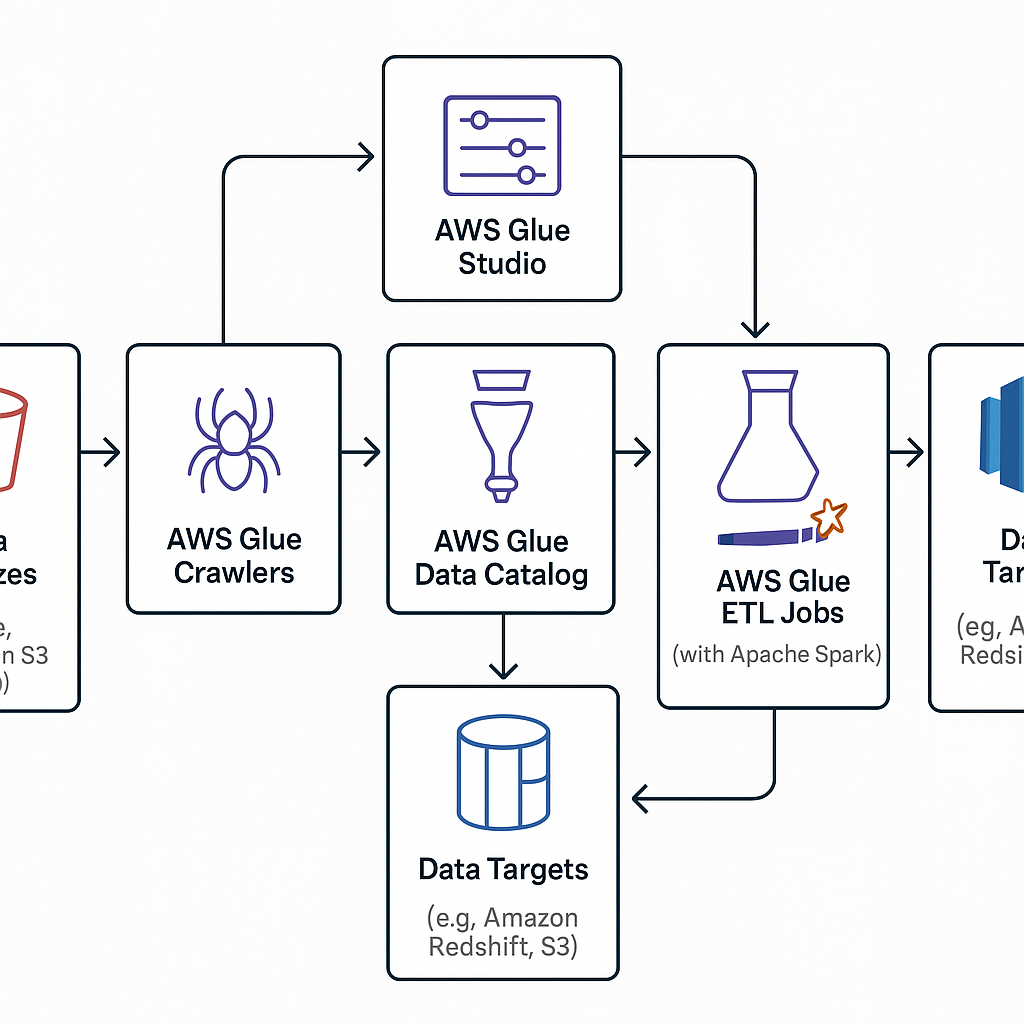
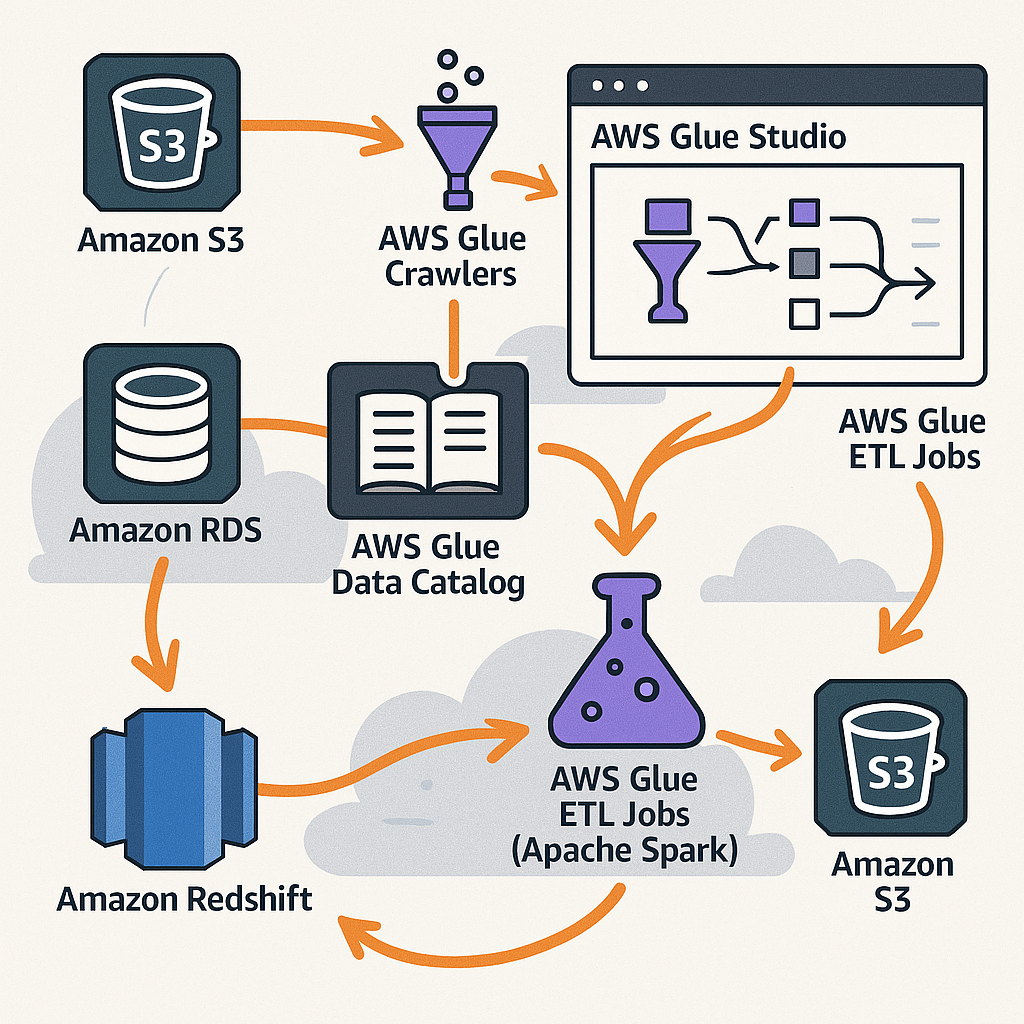
AWS Glue is a serverless ETL (Extract, Transform, Load) service designed to make it easy to prepare and load data for analytics. It automates much of the heavy lifting involved in data integration, including:
- Data discovery using crawlers
- Schema inference and cataloging
- Job orchestration with workflows
- Data transformation using Apache Spark or Python
- Integration with services like Amazon S3, Redshift, RDS, Athena, and more
Why Organizations Are Choosing AWS Glue
1. Serverless Simplicity
No infrastructure to manage. No provisioning. No scaling headaches. AWS Glue automatically scales to match your workload, allowing teams to focus on data logic instead of infrastructure.
2. Unified Data Catalog
Glue’s Data Catalog acts as a central metadata repository, making it easier to discover, govern, and share data across services like Amazon Athena, Redshift Spectrum, and EMR.
3. Built for Modern Data Lakes
Glue integrates seamlessly with Amazon S3, enabling organizations to build scalable, cost-effective data lakes. It supports popular formats like Parquet, ORC, JSON, and Avro.
4. Flexible Development Options
Whether you’re a data engineer writing Spark scripts or a data analyst using visual job editors, Glue supports both code-first and no-code development styles.
5. Cost-Efficiency
With pay-as-you-go pricing and no upfront costs, AWS Glue is ideal for organizations looking to optimize their data integration spend.
6. AI-Powered Data Preparation
Glue DataBrew allows users to visually clean and normalize data using over 250 pre-built transformations—no coding required.
🧠 Real-World Use Cases
- Retail: Integrating sales, inventory, and customer data for real-time analytics
- Healthcare: Normalizing patient records across systems for compliance and insights
- Finance: Automating ETL pipelines for fraud detection and reporting
- Manufacturing: Aggregating IoT sensor data for predictive maintenance
🛠️ How We Use AWS Glue at DappaTechnology
As part of our VisionStack portfolio, we leverage AWS Glue to:
Support our clients’ digital transformation journeys with scalable, secure data integration
Build hybrid cloud data pipelines
Enable multi-cloud data lake architectures
Automate data ingestion for analytics and AI workloads
Final Thoughts
AWS Glue is more than just an ETL tool—it’s a strategic enabler for modern data platforms. Its serverless nature, deep AWS integration, and flexibility make it a go-to choice for organizations looking to accelerate their data initiatives.
If you’re building a cloud-native data architecture or modernizing legacy ETL processes, AWS Glue deserves a spot in your toolkit.